
Corpus analysis: The Ugly Duckling of Translation
 Not long ago, hearing the term “corpus linguistics” made me shriek; after all, it was something that only linguists in academia did, right? So, when I signed up for a course, I was not fully convinced that I would learn something that I could truly put into practice. However, by the end of the course, I had concluded that corpus analysis is the Ugly Duckling of Translation.
Not long ago, hearing the term “corpus linguistics” made me shriek; after all, it was something that only linguists in academia did, right? So, when I signed up for a course, I was not fully convinced that I would learn something that I could truly put into practice. However, by the end of the course, I had concluded that corpus analysis is the Ugly Duckling of Translation.
Before you get to know it, it looks ugly and worthless, but as your relationship deepens, you start seeing the beauty of it. And don’t take my word for it; others have seen it too. Take my husband, for example, a freelancer translator with all the best tools. He had also heard about corpus analysis; he knew that learning how to analyze corpus might be useful, but he had not taken the time to do it. Once I showed him how easy it was to do searches, he was immediately hooked. He even built a huge corpus from his legal and oil & gas documentation, which are his specializations. Recently, after a 10-minute introduction to a colleague, she said: “OMG, where has this been all my life!”
If you haven’t been overcome by this feeling yet, I am willing to bet that you are still looking at the Ugly Duckling from the outside. But I am sure I can convince you in the next few paragraphs by showing you the face of a cute little swan. There are three easy steps to start believing.
The first step: Decide which tool you want to use. AntConc, Wordsmith, and Sketch Engine are some of the top names in the market. All of them are great tools. But you can start with AntConc (free) to take your first steps and then take advantage of the free trials and play with the others to pick your favorite. Of course, you could stick to using online corpus such as COCA, BNC, BNCweb, etc., and maybe that’s enough for you, but why not build your own corpus that can be controlled and expanded endlessly and effortlessly!
The second step is collecting your corpus and converting it to .txt files. Nothing easier! Create a folder with subfolders on your computer. For example, if you translate documents on energy, you can have two main folders, renewable and nonrenewable; then, inside the renewable folder, you may have wind energy, solar energy, bioenergy, etc. Why is this folder division important? Because sometimes you might be looking for a general term on renewable energy, but other times you only want to search in your documentation on solar energy, which could make your searches faster. If you are just starting out, don’t worry about the number of documents in the beginning, just make sure they are representative of the topic you are working with to make sure you get useful results. You can add more documents as you get the hang of it. Just remember: Quality over quantity!
Corpus analysis tools only accept .txt files, but you can find free software that can do this for you in a matter of seconds, including the collection of cute little tools provided by the creator of AntConc, Dr. Laurence Anthony. AntFileConverter and EncodeAnt help you convert PDF and Word files into .txt, and .txt files into UTF-8 files, respectively (“stubborn” .txt files that the tool may not recognize might need that extra step of conversion to UFT-8 files). The conversion takes seconds, even for a large number of documents.
The third step is getting training, free training, that is. I know what you’re thinking: That’s going to take a long time. Wrong! Take AntConc, for example, Dr. Anthony has a collection of 5 to 10-minute videos that explain every function clearly. The fact that they are short suggests that it doesn’t take long to understand how the software works. By the way, when I say “software” I am actually referring to a downloadable file. It can’t get any easier than that! If you are just starting out, don’t get overwhelmed. First, play with the concordance tool until you feel comfortable using it before going to the next one. And that’s it! If you complete those three steps. you are ready to play. And, really… Play! It is so much fun.
What do I use it for? Corpus analysis tools include many great functions. I look for terms to confirm that they have been previously translated in this or that way. You can see how many times each term has been used and make an appropriate decision. For example, “operational” in Spanish could be “operativo,” “operacional,” “de negocios,” etc. When I check my corpus, which has been translated by professional translators, I can see how every term is used in its context and make my choice.
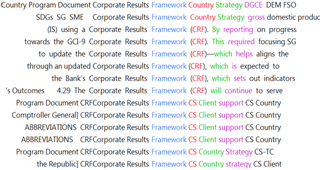 I can also “guess” a translation for a term to see if my guess is correct and, consequently, an accurate term for my translation. To illustrate, I can enter the word “framework” to search for a term that I know for sure contains it. I can sort my results by one, two or three words to the left or to the right (as shown by the colors red, green, and purple in the illustration) of the word “framework.” And I know it is an acronym, so I ask the program to look only for capitalized “Framework.” And, voilà, I get what I am looking for: Corporate Results Framework (CRF). If I click on Framework to see the context for every hit, the program takes me to the .txt file where the term came from. That is music to my ears.
I can also “guess” a translation for a term to see if my guess is correct and, consequently, an accurate term for my translation. To illustrate, I can enter the word “framework” to search for a term that I know for sure contains it. I can sort my results by one, two or three words to the left or to the right (as shown by the colors red, green, and purple in the illustration) of the word “framework.” And I know it is an acronym, so I ask the program to look only for capitalized “Framework.” And, voilà, I get what I am looking for: Corporate Results Framework (CRF). If I click on Framework to see the context for every hit, the program takes me to the .txt file where the term came from. That is music to my ears.
Another tool that is music to my ears is BootCat, which converts your favorite websites into a format that can be examined in a corpus analysis tool. It is super easy to use, and it is extremely valuable if you have to translate a document about a topic that you still don’t know that well. (Great for newbies!) Just search the web, select sites or pages about your topic, and copy the URLs into BootCat.
After that first course, my interest in corpus analysis grew. There are a few courses and webinars that show translators not only how useful they are but also how to use them. However, few of them are free. I must confess, I am not an expert, but I am a good player. And when you become a skillful player, you too will see the ugly duckling become a beautiful swan!
Header image: Pixabay
Author bio
 Patricia Brenes works in the Quality Control Unit of the Translation Section of the Inter-American Development Bank in Washington, D.C. She is a translator and terminologist, with a Master’s Degree in Specialized Translation from the University of Vic in Barcelona and certified by ECQA as Terminology Manager (TermNet, Vienna).
Patricia Brenes works in the Quality Control Unit of the Translation Section of the Inter-American Development Bank in Washington, D.C. She is a translator and terminologist, with a Master’s Degree in Specialized Translation from the University of Vic in Barcelona and certified by ECQA as Terminology Manager (TermNet, Vienna).
After realizing that there was a limited availability of resources and information for linguists and other stakeholders, she decided to start a terminology blog with resources and information: http://www.inmyownterms.com (Terminology for Beginners and Beyond).
I have also just published a post on Corpus Analysis and how it could help a translator on eMpTy Pages that your readers might find interesting at https://kv-emptypages.blogspot.com/2017/08/the-evolution-in-corpus-analysis-tools.html
Very interesting read, thanks for sharing, Kirti! We will retweet the article through Savvy’s account, so our followers can enjoy it. Would it be ok to reblog your post on Lingua Greca’s blog (http://linguagreca.com/blog/)?
[…] Next for Canada’s Translation Bureau Fixing in-house review: Bob the Builder to the rescue Corpus analysis: The Ugly Duckling of Translation 5 tips for learning a new language more effectively Career question: Do I really need to learn […]